اعلام خاتمه و شکست پروژه Bugg.ir + درسهایی که آموختم
داستان شروع و شکست یک پروژه شخصی و درسهایی که در اجرا، نگهداری و زمان شکست این پروژه آموختم.
داستان چیه؟
چند سال پیش وقتی پروژهها زیاد شد، پشتیبانی پروژهها هم بیشتر شد. اون موقع ما کتابخانهای به نام elmah رو به خود پروژهها اضافه میکردیم. این کتابخانه که یک کتابخانه لاگر بود، مثل بقیه کتابخانههای مشابه میتونست لاگها را به خروجیهای مختلفی بفرسته. ما دیتابیس رو انتخاب کرده بودیم. در واقع در کنار جداول اصلی پروژه در دیتابیس، یک جدول هم مخصوص نگهداری لاگها بود. علاوه بر این یک UI تحت وب هم برای لیست کردن لاگها به پروژه اضافه میشد. این روش ۲ مشکل داشت: یکی اینکه حجم دیتابیس رو بالا میبرد و دوم اینکه برای دیدن لاگهای هر پروژه باید به آدرس همون پروژه میرفتیم. اینجا بود که به فکر استفاده از یک سرویس مرکزی تحت وب برای ذخیره کردن و جستجوی لاگهای همه پروژهها به صورت متمرکز افتادم.
بر پایه schema لاگهای elmah که ما استفاده میکردیم سایتی بود به نام elmah.io که سرویس ابری برای ذخیره کردن لاگها ارائه میداد. دامنهای که این نوشته رو الان ازش میخونید یعنی elmah.ir قرار بود پروژه مشابهی رو داشته باشه که بعداً جای خودش رو داد به bugg.ir
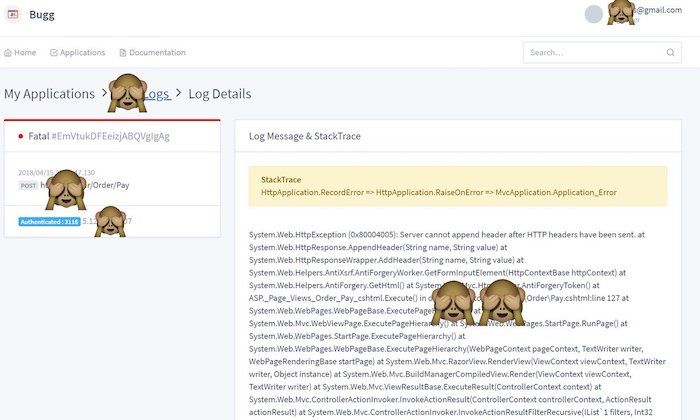
پروژه bugg.ir بر پایه NLog بود و در واقع یک target ابری برای schema لاگ NLog محسوب میشد. وقتی راهاندازی شد کمک بزرگی بود. باعث شد لاگ همه پروژههای تجاری و حتی بعضی پروژههای شخصی رو یکجا داشته باشیم.
در واقع bugg.ir که میشد باگگیر خوندش یک اینترفیس تحت وب برای مشاهده لاگهای ثبت شده پروژهها بر اساس schema کتابخانه NLog رو میداد. اولش قرار بود فقط برای پروژههای داخلی خودمون استفاده بشه اما به این فکر کرده بودم که برای دولوپرهای دیگه هم در دسترس باشه.
باگگیر شکست خورد، اما چرا؟
بیش از یک سال از پروژه bugg.ir استفاده شد. همونطور که گفتم کمک بزرگی بود. اما بالاخره تصمیم گرفتم پروژه رو تعطیل کنم. آخرین وضعیت bugg.ir بتای خصوصی بود و قبل اینکه به بتای عمومی برسه، خاتمه پیدا کرد. اما چرا؟
- وابستگی به NLog: یکی از مهمترین دلایل اتمام پروژه این بود که بر اساس schema استاندارد کتابخانه NLog کار میکرد. پس همیشه محدود به این کتابخانه بودیم.
- مصرف منابع بالا: لاگها دستهبندیهای مختلفی دارند، بعضی وقتها فقط خطاها رو لاگ میکنیم اما بعضی وقتها هم لازمه کل پروسه اجرای یک عملیات رو به صورت کامل ببینیم. در واقع اتفاقات رو Trace کنیم. این یعنی حجم اطلاعات ارسالی که نیاز به ذخیرهسازی دارند به شدت بالاست. وقتی برای چند پروژه محدود این کار رو انجام بدین زیاد مشخص نمیشه اما هر چه تعداد پروژهها بیشتر بشه، این حجم به شدت افزایش میکنه و منابع بیشتری صرف پردازش لاگها میشه.
- هندل کردن همزمانی: یکی از مهمترین مشکلات اینکه خودتون یک سرویس لاگ مرکزی بنویسید اینه که API شما تا چه اندازه میتونه لاگ همزمان پروژههای مختلف رو دریافت و پردازش کنه. گرچه این مورد هم به نوعی به منابع برمیگرده اما برنامهنویسی هم قطعاً تاثیرگذاره.
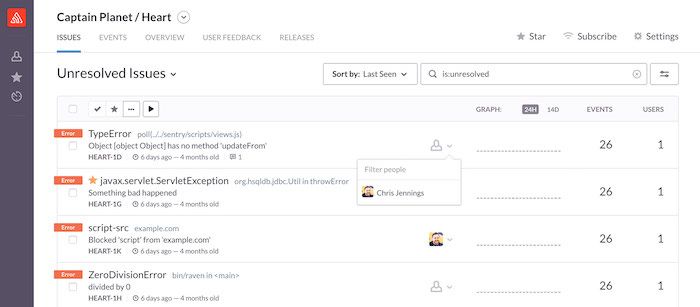
- رقبای جدی خارجی: سایتهای خارجی مختلفی هستند که این خدمات رو ارائه میدن. همه این سرویسها غیررایگان هستند اما بعضیشون پلنهای رایگان با محدودیت دارند. یکی از معروفترینهاشون که تقریباً لاگ هر چیزی رو میشه بهش فرستاد sentry هست. مزیت اصلی سرویسهای خارجی اینه که کتابخانههای مختلف رو پشتیبانی میکنند و منحصر به ساختار یک کتابخانه نیستند. سرویسهای دیگری هم هستند اما sentry از نظر من این حسن رو داره که گردش کارش برای حل کردن مشکلات و یکپارچگیش با زبانها و کتابخانههای مختلف خیلی خوبه و صدالیته حتی با وجود اینکه در استفاده از سرویس ابری sentry تحریم هستیم ولی نرمافزار سرورش رو میتونیم دانلود و به صورت self-hosted برای خودمون راهاندازی کنیم.
درسها و نکات برای انتخاب یک سرویس ابری لاگ
- schema اختصاصی داشته باشید اما منحصر به آن نباشید. چه انتخاب میکنید که از سرویس ابری استفاده کنید، چه روی سرور خودتان نرمافزار را نصب میکنید و چه راهکار اختصاصی خودتان را ایجاد میکنید لازم است یک ساختار اختصاصی برای ذخیره رویدادهای لاگ داشته باشید. اما ارسال لاگها را به آن ساختار محدود نکنید. در واقع آداپتر برای کتابخانههای دیگر ایجاد کنید که ساختار ذخیره دادهشان را به ساختار مورد نظر شما تبدیل کند.
- اگر سرویسهای ارائهدهنده ثبت و جستجوی لاگ را ببینید، متوجه میشوید همه آنها پلنهای پولی دارند و معمولاً محدودیتهای پلن رایگان آنها به شکلی است که استفاده از آن چندان کاربردی نیست. مثلاً زمان ذخیرهسازی لاگ بسیار محدود مثلاً یک هفته است. دلیل این مساله تنها نگاه تجاری نیست، بلکه واقعاً ذخیرهسازی و پردازش اطلاعات انبوه لاگها، منابع زیادی نیاز دارد. اگر به گزینه self-hosted یا ارائه سرویسی در این خصوص فکر میکنید حتماً پول خوبی برای هزینه سرور کنار بگذارید.
- وقتی یک crash reporter یا سرویس ذخیره لاگ میسازید، ثبت لاگها و جستجو در آنها لازم است اما کافی نیست. باید به فکر ایجاد یک گردش کار برای رفع باگها باشید. این گردش کار میتواند به صورت یکپارچه با سیستم شما باشد یا با سرویسهای دیگر (مثلاً گیتهاب یا گیتلب) یکپارچه باشد. در هر حال راهی پیدا کنید که خطاهای مجتمع شده را برای رفع، برنامهریزی کنید.
- سرویسهایی که با اطلاعات انبوه سر و کار دارند، حتماً نیازمند تستهای بیشتری از جمله load test هستند.
- uptime سرور/سرورها در این نوع محصولات بسیار مهم است. down بودن سرور در این سرویس، حکم گندیدن نمک را دارد. دیتاسنترهای داخل کشور برای این کار مناسب نیستند. سرویس
bugg.irهم از این اختلالات اینترنت داخل کشور دچار مشکل شد. اگر به دلیلی مجبور به استفاده از سرورهای داخل ایران هستید، timeout مناسبی را در کتابخانه لاگ خود در نظر بگیرید که در صورت down بودن سرور مرکزی، نرمافزار شما به دلیل انتظار برای سرآمدن timeout اتصال به سرور ارسال لاگ، کند نشود. - چه در انتخاب یک سرویس ابری برای لاگ و چه در ساخت یک سرویس برای ثبت و جستجوی لاگها، به خروجیها دقت کنید. مهم است سرویس انتخابی یا ایجاد شده توسط شما، امکان اتصال به سرویسهای دیگر یا حداقل پشتیبانی از web hook را داشته باشد تا در رویدادهای مهم (مثلاً لاگهای fatal) بتواند تیم توسعه را از بروز مشکل جدی مطلع کند.
تحریمها و قیمت دلار، انتخاب سرویس ابری لاگ رو برای دولوپرهای ایرانی سخت کرده، جای یک سرویس مطمئن ثبت و جستجو و اطلاعرسانی لاگ برای ما خالیه!